
Building Autonomous AI Agent for Web-Based Tasks
Imagine automating complex, multi-step tasks-booking a multi-leg flight, analyzing competitor product launches, or performing detailed data entry across different web applications. These tasks require more than just following instructions; they demand an understanding of the overall goal and the ability to adapt when the unexpected happens.
This is where the paradigm of a closed-loop autonomous agent comes in. Instead of executing a fixed sequence of commands, this agent understands a high-level task, observes its environment, reasons about the next best action, and acts-creating a continuous feedback loop that makes it resilient, adaptable, and remarkably powerful.
This article details the novel architectural solutions I developed while building an autonomous web agent from first principles. It chronicles the journey of identifying core engineering challenges and creating the specific innovations required to make the agent genuinely reliable.
In the following sections, I will walk you through the evolution of this agent. We’ll start with the high-level architecture and the core principles that guided its design. Then, I’ll dive into the critical failures I encountered when testing this system against the modern web-from unreliable selector generation to the nuances of element interactability and state synchronization. Finally, I’ll detail the “Task Offloading” strategy that led to a more resilient agent, showcase its capabilities with real-world demos, and discuss the essential security considerations for developing such systems responsibly.
The Goal: The premise was simple. Give the agent a single, high-level task and a starting URL, with no other specific instructions. The expectation is that the agent will autonomously interpret this high-level intent and generate the concrete sequence of UI interactions required to achieve it. For example:
Task: “Search jobs for the role of Data Scientist in India with a salary between 50 LPA to 100 LPA.”
Start URL: “https://www.naukri.com/“
Why is this a hard problem?
The modern web is a chaotic, dynamic environment. Websites are not static documents; they are complex applications with pop-ups, asynchronous loading, and ever-changing layouts.
Core Properties of a Resilient Autonomous Web Agent
To succeed in this chaotic environment, an agent must exhibit a set of crucial, intelligent properties that can be grouped into three main categories:
- Advanced Reasoning and Planning: A resilient web agent must strategically decompose high-level goals into multi-step plans while using a working memory of its progress to avoid getting stuck in loops and recover from errors.
- Robust Perception and Environmental Understanding: Its perception must be robust, allowing it to be effectively interact with its environment. Crucially, it must detect when its own actions cause the state to change, forcing it to re-evaluate its environment before proceeding.
- Safe and Principled Operation: Finally, the agent must operate safely with privacy by design, recognise insurmountable obstacles like a CAPTCHA, and have security guardrails against destructive actions.
High-Level Architecture
The design of this web agent is based on the classic OODA Loop (Observe, Orient, Decide, Act). It has 3 main components.
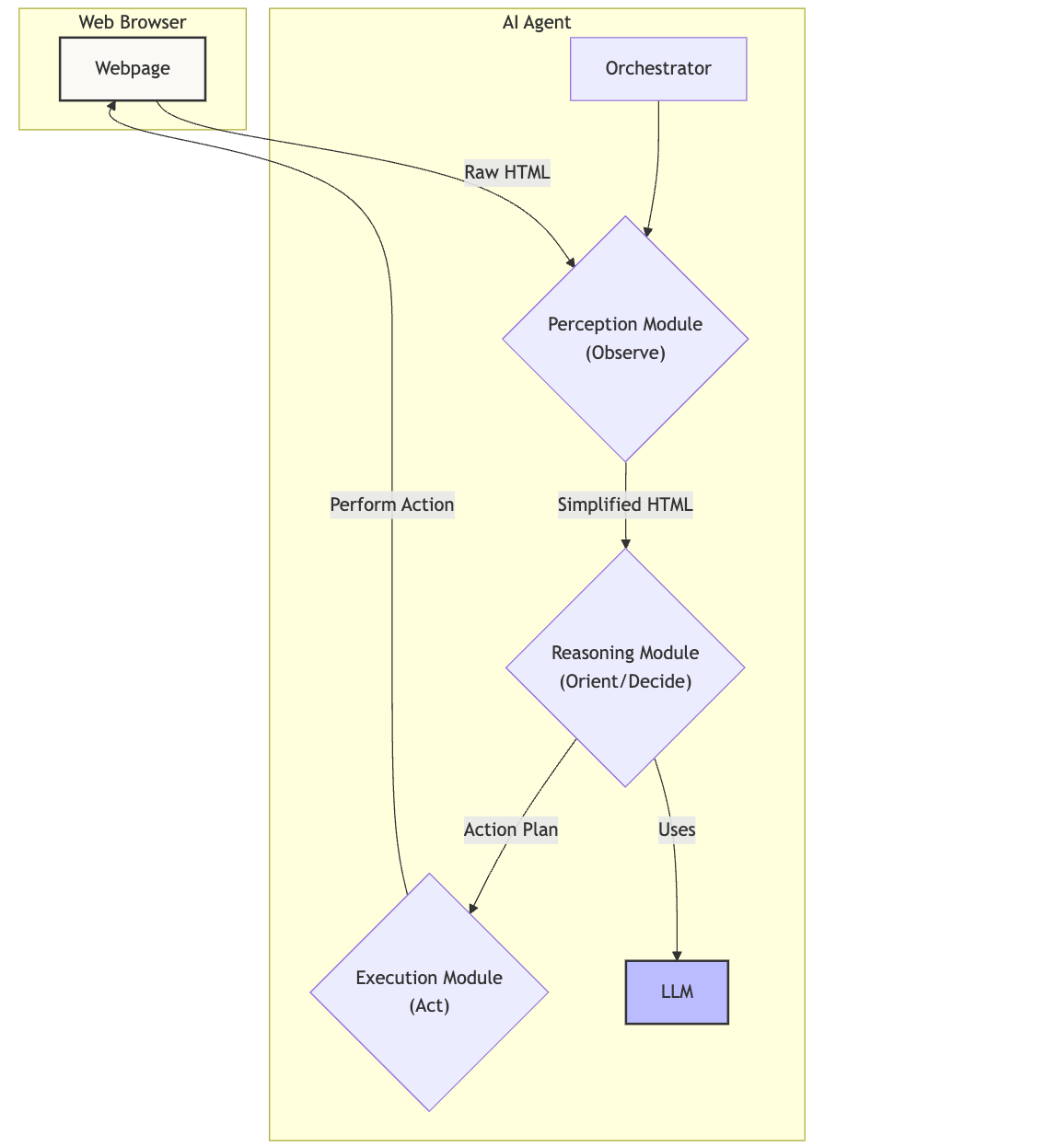
Perception: The agent’s eyes. The module handles the “heavy lifting” of deterministic tasks to provide rich, reliable data to the Reasoning module. It takes a raw HTML page and converts it into a cleaned version removing all the unnecessary details.
Reasoning: The agent’s brain is implemented using LLM . Focuses on high-level strategy, decomposing the goal and creating plans based on the data provided by the Perception module. The LLM takes the high-level task, looks at the cleaned HTML page, the past actions it has taken and errors (if any), and then generates an action plan. E.g. For ‘naukri.com’ example provided above, the expected behaviour is
- The High-level task is “Search jobs for the role of Data Scientist in India with a salary between 50 LPA to 100 LPA.”
- LLM looks at the cleaned version of the web page, identifies that there are input boxes to enter “skills/designations” and “Location” and generates below plan
plan = {
{"COMMAND": "TYPE", "SELECTOR": "#CSS selector for skills/designations input box", "VALUE": "Data Scientist"},
{"COMMAND": "TYPE", "SELECTOR": "#CSS selector for location input box", "VALUE": "India"},
{"COMMAND": "CLICK", "SELECTOR": "#CSS selector for search button", "VALUE": "null"},
}Execution: The agent’s hands. Executes the plan generated by the Reasoning module using a browser automation tool. For the example mentioned above, it would take the plan generated above and execute the commands in order.
A central Orchestrator code runs this loop continuously, connecting all the other modules until the task is complete. This forms a continuous feedback loop. For our example above, the loop would continue to the next page which displays the jobs for the role “Data Scientist” in “India”.
This looks like a fairly simple architecture, real challenge though, I learned, was in perfecting the quality of information flowing between these modules.
Guiding Principles
Below are some of the important guiding principles that drove the implementation of this web agent.
- The agent’s brain (the LLM), is expected to possess only core capabilities such as instruction following, structured data generation, HTML understanding and optional multi-modal understanding, i.e. it should be a capable model but we make no assumptions regarding its advanced reasoning capabilities.
- The agent’s central orchestrator - the code that manages the agent’s actions and state, should always be deterministic to provide explicit controls, safety guardrails, and predictable logic. We will not delegate this core control flow to a non-deterministic LLM.
- The environment state that LLM sees, should be a cleaned but near raw HTML which provides additional context to the reasoning module, so that it can “look ahead” and generate a multi-step action plan when possible.
- We do not provide the agent (specifically the LLM), with any specific set of instructions w.r.t. the Task (at least for the current version). We only define a generic, standard operating procedure for the agent.
- The deterministic components of the Agent should be scalable.
- We implement this agent from first principles using Python and Playwright. We do not use any Agent Framework. When testing novel concepts, it is crucial to have full control over the execution loop to ensure our experimental logic performs exactly as designed, free from the potential side-effects of a framework’s abstractions.
Implementation: First Attempt
My first attempt at building such a system, guided by my intuition and experience of working with LLMs, turned out to be not so successful. The agent struggled with simple tasks. The issue? Well, there were plenty.
- Un-reliable selector generation: The LLM struggled to generate reliable selectors that could uniquely identify HTML elements. E.g. The LLM could generate a plan to “TYPE” text “Data Scientist” into “skills/designation” input box with the CSS selector “.suggestor-input” which could resolve into multiple input elements, instead of the single “skills/designation” input element we expect and the execution would fail.
- The Nuances of Interactability and Visibility: The LLM was not able to understand that an element was outside of the browser viewport and not interactable. Or, although there is this button that it could see in raw HTML, it was occluded by a modal window. E.g. In case of ‘naukri.com’, the LLM would report to click on “View More” for a salary filter, not realising it was outside the browser viewport and non-interactable.
- Intra-plan state change: LLM’s multi-step action plan was based on, not only the current page state but its assumptions about future states, which lead to failures while executing the plan. A static plan generated by the LLM could become instantly invalid if an early action triggered a state change. A flight search on travel website is a perfect example. Given a high-level task “Search for a flight from New York (JFK) to Los Angeles (LAX) for next Friday, for two adults.” The LLM generates a sensible plan:
plan = {
{"COMMAND": "TYPE", "SELECTOR": "#CSS selector for source input box", "VALUE": "New York (JFK)"},
{"COMMAND": "TYPE", "SELECTOR": "#CSS selector for destination input box", "VALUE": "Los Angeles (LAX)"},
{"COMMAND": "CLICK", "SELECTOR": "#CSS selector for search button", "VALUE": "null"},
}- However, the first TYPE action itself would trigger a JavaScript event that would make an autocomplete dropdown to appear. To select a valid source, the agent needs to “CLICK” on first valid option. The action plan is no longer valid now because state of the web page has changed.
The Solution: Tasks Offloading
My initial hypothesis was that LLMs with their massive context windows and profound understanding of unstructured data, could operate effectively on near-raw HTML, identify the html elements, corresponding selectors and precisely generate the multi-step action plan. Well, the LLMs could still do these tasks separately, in silos, when engineered with a specific set of prompts, examples etc. It struggled in this particular setup because I was asking a single LLM call to perform multiple, distinct cognitive tasks simultaneously: 1. Decompose the high-level goal, 2) Reason about the next logical action, and 3) Generate the precise, technically-correct CSS selector for that action, which caused ‘cognitive overload’. The model would correctly prioritise the high-level reasoning (“I need to click the search button”), but its selector generation became a secondary, less reliable output.
The immediate next step I tried to handle some of these issues was to improve the standard operating procedure for the agent - in prompt instructions. But, that didn’t yield expected LLM behaviour.
Next, I decided to decouple the tasks the LLM was struggling with, from the reasoning module to the deterministic components of the Agent and let the LLM do what it was doing best - reason about the current state and come up with a precise plan of actions to solve the high-level goal. These changes are discussed below.
Augmented HTML and Reliable Selector generation
I re-architected the Perception Module to augment the HTML before sending it to the LLM. For every interactive element, the perception code now runs a multi-strategy process to find a guaranteed unique selector and embeds that directly into HTML code as element attribute agent-selector. The LLM no longer needs to invent new selector for each action. It can just return the pre-validated selector it can find in the HTML code.
Handling the nuances of Interactability and Visibility
For each interactive element, the Perception module also calculates its state, whether it is INTERACTABLE or NON_INTERACTABLE. This state is directly embedded into the HTML code passed to the LLM as agent-state. So, In case of our previous example, the LLM determines it needs to click on “View More” to see the salary filter but the state for the filter is “NON_INTERACTABLE”, so the next logical action it needs to take is SCROLL down the page, so that the filter is INTERACTABLE. You can see agent handling this particular case in the demo video below.
State Synchronisation:
The issue of Intra-plan state change was handled using a combination of steps below.
- The Perception module, calculates the page ‘DOM’ signature.
- For each action in the plan, the Execution module now checks the page signature before and after executing the action. If the page signature is different, it means the page state has changed, the execution code discards any further actions in the plan and initiates the agent loop again so that LLM can perceive the new page state. In our flight search example above, after first TYPE, the new autocomplete dropdown appears, the page signature has changed, so the Execution module discards any further actions and restarts the agent loop. The LLM can now see the autocomplete dropdown and generate new action plan accordingly.
Demo: Autonomous Web Agent in action
To demonstrate these capabilities in a real-world context, I’ll now present two examples. The tasks themselves—filtering jobs on a career portal and finding a restaurant on a review site—are intentionally familiar. However, their execution reveals the hidden complexities of modern web applications and showcases the agent’s advanced planning, adaptive perception, and resilience when faced with dynamic UIs and unexpected obstacles. In the demo below, you can see the agent in action: the left pane shows the live browser where it performs its tasks, while the right pane reveals its ‘thought process’—the real-time logs, reasoning, and action plan for each step.
Demo 1: The below demo shows the use-case I have discussed throughout this article.
- Task: “Search jobs for the role of Data Scientist in India with a salary between 50 LPA to 100 LPA.”
- Start URL: “https://www.naukri.com/”
The above demo showcases several crucial properties working in concert to solve a complex, multi-step task without any hand-holding. The key behaviours the agent is exhibiting are:
- Successful Goal Decomposition and Planning:
- What it is: The agent was given a single, high-level goal “Search jobs for the role of Data Scientist in India with a salary between 50 LPA to 100 LPA”. In Step 1, its thought process shows it correctly decomposed this goal into a logical sequence of sub-tasks: (1) Perform the initial search, and (2) Apply the salary filter on the next page.
- Why it’s crucial: This demonstrates true reasoning. It didn’t just look for a “salary” field on the homepage; it correctly inferred that filtering is a secondary step that happens after a search, showcasing its ability to form a high-level strategy.
- Intelligent Action Batching and State Awareness:
- What it is: The agent’s controller code correctly executed multiple actions from a single plan when the state was stable, but immediately stopped when the state changed. In Step 1, it executed two TYPE commands without needing a new LLM call, but correctly broke the plan after the state-changing CLICK command. The same thing happened in Step 4, where it correctly grouped the two checkbox CLICKs with the final, state-changing “Apply” CLICK.
- Why it’s crucial: This is the “best of both worlds” solution. It’s efficient (fewer LLM calls) but also safe, as it never acts on stale information.
- Robust Environmental Perception and Self-Correction:
- What it is: The agent is not just blindly following a plan; it’s using the agent-state information to understand the “physics” of the page and adapt its strategy. In Step 2, the agent’s thought correctly notes that the “View More” link is NOT_INTERACTABLE. Instead of failing, it correctly hypothesizes that the element is off-screen and that the appropriate action is to SCROLL. This shows it understands the meaning of the augmented state data.
- Task Completion and Loop Avoidance:
- What it is: The agent correctly recognizes when it has fulfilled all the criteria of the task and terminates successfully. In Step 5, after applying the filters, the agent assesses the state and concludes that the task is complete.
- Why it’s crucial: This demonstrates that the agent is able to reach a correct terminal state.
Demo 2. Below agent run showcases another interesting example of agent’s ability to correctly identify an impasse.
Task: “Find the highest-rated Italian restaurant near the Empire State Building. Get the address of the top restaurant.”
Start URL: “https://www.yelp.com.”
The agent shows similar properties as in previous case. The agent when presented Yelp homepage with a search form, identifies the input ‘find_desc’ and types “Italian”. Next it sees that for ‘find_loc’, the location input is set to ‘San Francisco, CA’, and it needs to update the location to ‘Empire State Building, New York, NY’. After successfully submitting the search, the agent was presented with a DataDome CAPTCHA, a common anti-bot measure designed to stop automated scripts. It knows that it cannot interact with the CAPTCHA iframe directly to solve it and hence, cannot proceed further with the task. It stops, reporting the appropriate reason. This demonstrates safety and reliability. The agent understands its own limitations. For any real-world application, knowing when to stop and report a clear reason is just as important as knowing how to proceed. It allows a human supervisor to understand the problem immediately.
Engineering for Trust: Addressing Security and Privacy
From the outset, building a secure and private agent should be a primary design consideration. A powerful autonomous agent introduces significant responsibilities that must be addressed at an architectural level.
The Risks:
The primary risks fall into two categories: data exposure and unintended actions.
- Data Exposure to Third Parties: Sending raw page content can leak user PII, confidential business data, or session tokens embedded in the HTML to the LLM provider.
- Implementation Vulnerabilities: A malicious website could use Prompt Injection to hijack the agent’s mission, or the LLM could be tricked into performing destructive actions (like clicking “Cancel Order”) without explicit consent.
The Mitigation Strategy:
The agent’s orchestrator code must act as a strict security guard.
- Aggressive DOM Scrubbing: The Perception Module must be enhanced with a “scrubber” that redacts PII patterns and, most importantly, removes the value from all form fields before sending the HTML to the LLM.
- Controller-Level Sandboxing: The orchestrator must enforce hard-coded rules, like using a domain whitelist for sensitive tasks and requiring human confirmation for actions that involve keywords like “delete,” “purchase,” or “cancel.”
- Strengthened System Prompts: The LLM must be explicitly instructed to ignore any commands it finds on a webpage and to adhere only to the user’s original task.
This is not an exhaustive list, and as agent capabilities evolve, a continuous and thorough exploration of the security and privacy landscape is essential to ensure responsible development.
Limitations and Next Steps
It is crucial to be transparent about the limitations of this current system, especially regarding security and privacy. While the core architecture for a secure agent has been outlined, the necessary guardrails—such as aggressive PII redaction and sandboxing for destructive actions—have not yet been implemented. It will need a thorough security review before such system can be used for practical purpose. Beyond this foundational concern, the agent can still suffer from a form of “Context Amnesia” occasionally failing to use its history effectively to avoid loops, which highlights the need for a more advanced memory system. Furthermore, it struggles with complex, data-driven procedures (like comparing prices) and its perception is confined to the HTML DOM, leaving it blind to <canvas> elements or OS-level interactions like file uploads.
The system I’ve developed, therefore, stands as an advanced prototype—a robust proof-of-concept that successfully demonstrates a resilient architecture for web automation. While it excels at navigating dynamic UIs and recovering from common errors, its limitations define the path forward. It currently lacks long-term memory to learn from past tasks and the deeper reasoning required for complex data comparison. Crucially, as noted, security and privacy mitigations must be fully implemented, and any use of this agent should be undertaken with extreme caution on non-sensitive, public websites only. The next steps are clear: to evolve this framework by building out these essential security guardrails and integrating a memory system, transforming this powerful prototype into a truly intelligent and trustworthy assistant for the web.